Portfolio

Meta AI Sales Bot for an SMM Agency
Sales scripts encode something specific: a model of the conversation, and the logic for navigating it based on what the customer says. Translating that into a reliable automated system is mostly an engineering problem — the challenge isn't generating responses, it's making sure the right response is selected consistently.
This project involved taking a client's sales methodology and restructuring it into a configurable system: dialogue flows, branching logic, objection handling at different stages of the conversation, and fallback behaviour for unexpected inputs. The language model handles intent recognition at each step; the business logic handles everything else. Responses come from the script, not from the model.
Because the business logic is fully separated from the model layer, the same system can be configured for different clients and verticals without rebuilding anything from scratch — which matters for an agency managing multiple accounts.
RAG Assistant for Zotero
A desktop application for semantic search over Zotero research libraries. Designed for researchers who need to navigate large literature collections and get answers with clear source attribution — not summaries that obscure where the information came from. Supports local LLMs for full data privacy. Open source.
View on GitHub →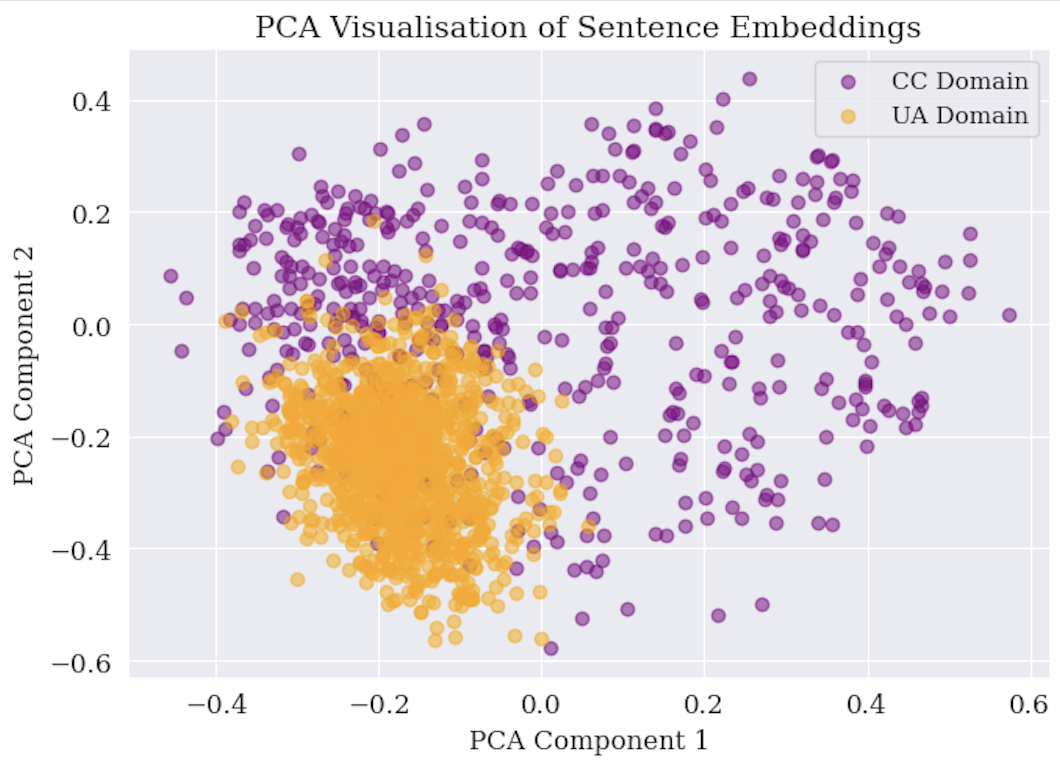
Model Robustness Under Distribution Shift (MSc thesis, UvA 2025)
An empirical study of whether multi-task learning can improve NLP model robustness when input or label distributions shift between training and deployment. The experimental setting was persuasion detection across two domains — Ukraine conflict and climate change — confirmed to be meaningfully different before any modelling began.
The central finding: multi-task learning helps most in low-resource, class-imbalanced settings, where the auxiliary task provides indirect data augmentation. In stable, data-rich settings, single-task models remain competitive.